지난 글쓰기를 보니 내가 List 인터페이스에 대해서는 설명을 그다지 많이 하지 않았는데
Queue에 대해서 이야기를 많이 했더니 PriorityQueue에 대해 제대로 설명하지 않았다.
프라이어리티큐는 이런 느낌이다.
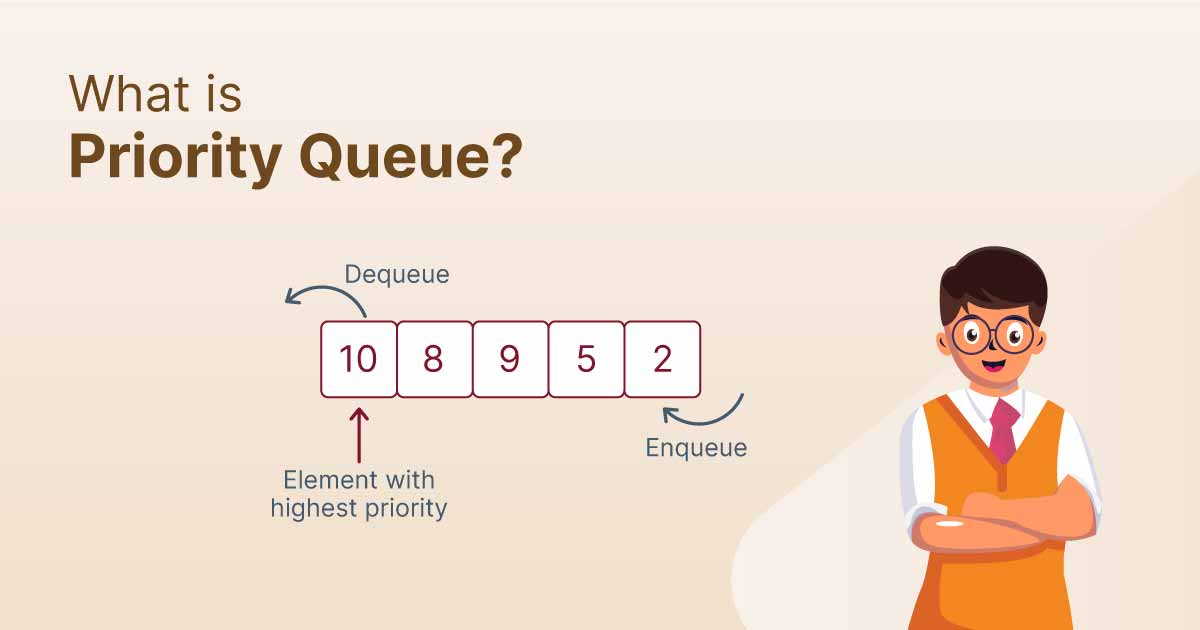
PriorityQueue는 Java에서 제공하는 표준 라이브러리 중 하나로, 자동으로 요소들이 우선 순위에 따라 정렬되는 큐 구현체입니다. 이 구현체는 내부적으로 힙(heap) 자료구조, 특히 최소 힙(min-heap)을 사용하여 요소들을 관리합니다. 이는 각 요소가 추가될 때마다 자동으로 정렬되어, 가장 낮은(또는 가장 높은, 정렬 기준에 따라 다름) 요소가 큐의 맨 앞에 위치하게 됩니다.
PriorityQueue의 주요 특징
- 자동 정렬: 요소가 추가될 때마다 자동으로 정렬이 이루어지며, 이는 자연 순서(Comparable 인터페이스 구현) 또는 제공된 Comparator에 의해 결정됩니다.
- 데이터 접근: 큐에서 데이터를 꺼내거나 확인할 때 항상 가장 우선 순위가 높은 요소(정렬 순서상 가장 앞에 있는 요소)부터 접근합니다.
- 효율성: 요소의 추가 및 제거 작업은 O(log n)의 시간 복잡도를 가지며, 요소의 조회는 O(1)입니다.
오름차순으로 할지 내림차순으로 할지는 설정하면 되는 것이고 요소를 넣으면 '자동 정렬'된다.
그런데 난 여기까지 보니까 이 생각이 들더라.
(본 블로그에 아직 안 올라왔지만) 요소가 삽입되면 우선 순위(중요도)에 따라 자동 정렬(오름차순, 내림차순, 뭐든)되는 건,
트리맵도 있고 트리셋도 있잖아???
Java에서 PriorityQueue와 유사하게 자동 정렬 기능을 제공하는 다른 컬렉션 구현체는 TreeMap과 TreeSet입니다. 이들은 레드-블랙 트리(red-black tree)를 내부적으로 사용하는 자료구조로, 모든 요소가 정렬된 상태를 유지합니다. 이것은 PriorityQueue의 힙 구조와는 다른 자료구조입니다.
(레드-블랙 트리는 내가 아직 온전히 이해를 못 했다. 🥹 레블트 어려워, 진짜로... 이건 나중에 따로 다룰 것이다.)
TreeMap
- 자동 정렬: TreeMap은 키를 기준으로 정렬하며, Comparator를 제공하여 오름차순 또는 내림차순 정렬을 설정할 수 있습니다.
- 키-값 쌍: TreeMap은 키-값 쌍(key-value pairs)을 저장하는 맵(map)이며, 각 키에 대해 정확히 하나의 값이 매핑됩니다.
- 정렬된 맵: TreeMap의 모든 키는 정렬된 상태를 유지합니다. firstKey(), lastKey(), subMap(), headMap(), tailMap()과 같은 메서드로 정렬된 키에 접근할 수 있습니다.
TreeSet
- 자동 정렬: TreeSet은 TreeMap을 내부적으로 사용하여 요소를 저장하며, 이 또한 Comparator로 정렬 순서를 정할 수 있습니다.
- 유일한 요소: TreeSet은 중복을 허용하지 않는 유일한 요소들의 집합을 저장합니다.
- 정렬된 집합: TreeSet의 모든 요소는 정렬된 상태를 유지합니다. first(), last(), subSet(), headSet(), tailSet()과 같은 메서드로 정렬된 요소에 접근할 수 있습니다.
PriorityQueue
- 자동 정렬: PriorityQueue는 내부적으로 최소 힙 또는 최대 힙을 사용하여 요소를 정렬합니다.
- 힙 구조: 요소를 추가할 때마다 바로 정렬되지 않고, 부모 노드가 자식 노드보다 항상 작은(또는 큰) "힙" 조건을 만족합니다.
- 데이터 접근: poll(), peek() 등을 사용하여 가장 우선 순위가 높은 요소에 접근할 수 있지만, PriorityQueue는 전체 정렬 상태를 유지하지 않습니다. 즉, 요소를 순회할 때 정렬된 순서를 보장하지 않습니다.
네? 아까는 자동 정렬 된다며...
그 얘기 하기 전에 하던 얘기 마무리 먼저 하자.
셋의 차이점
- 내부 구조: TreeMap과 TreeSet은 균형 이진 탐색 트리 구조, PriorityQueue는 힙 구조를 사용합니다.
- 성능: 일반적으로 TreeMap과 TreeSet은 요소의 추가, 삭제, 탐색에 O(log n) 시간이 걸리며, PriorityQueue도 유사한 O(log n) 시간 복잡도를 가지지만, 우선 순위에 따른 접근은 O(1)입니다.
- 용도: PriorityQueue는 주로 우선 순위가 가장 높은 요소에 빠르게 접근해야 할 때 사용되고, TreeMap과 TreeSet는 전체적인 정렬 상태를 유지하며 범위 검색이나 정렬된 순회가 필요할 때 사용됩니다.
PriorityQueue는 내부적으로 힙(heap) 자료구조를 사용합니다. 여기서 "힙"은 완전 이진 트리의 한 형태로, 모든 부모 노드가 자식 노드보다 작거나 큰 순서를 유지하는 반 정렬 상태(semi-ordered state)를 말합니다.
바로 정렬되지 않음
요소가 PriorityQueue에 추가될 때, 새 요소는 즉시 올바른 위치로 이동하지 않습니다. 대신, 힙 구조는 부모 노드와 자식 노드 간의 관계만 유지하면서 힙 조건을 만족시킵니다. 이는 힙의 루트(또는 최상단)에는 항상 최소 요소(min-heap의 경우)가 위치하도록 보장하지만, 나머지 요소들은 완전히 정렬된 상태를 유지하지 않습니다.
전체 정렬 상태 유지 안 함
PriorityQueue를 순회할 때(예: iterator 사용), 요소들은 힙 구조에 따라 정렬된 순서대로 반환되지 않습니다. 대신, poll()이나 remove()를 호출할 때마다, PriorityQueue는 힙의 루트 요소를 반환하고, 이 요소를 제거한 후 나머지 요소들을 다시 힙 구조에 맞게 재정렬합니다.
즉, PriorityQueue는 전체 요소가 완전히 정렬된 상태를 유지하는 것이 아니라, 힙의 특성을 이용하여 가장 우선 순위가 높은 요소(루트)만 빠르게 접근할 수 있도록 하는 구조입니다. 따라서 PriorityQueue에서는 poll()이나 peek() 같은 연산을 통해서만 최소/최대 요소에 접근하는 것이 바람직합니다.
정리하면, PriorityQueue는 내부적으로 요소들이 힙의 속성에 따라 부분적으로 정렬된 상태를 유지하지만, 전체 리스트와 같은 완전히 정렬된 구조는 아니라는 점입니다. 이것이 PriorityQueue와 배열이나 TreeSet/TreeMap과 같은 정렬된 컬렉션과의 주된 차이점입니다.
내가 전체 내용을 수정하려다가, 일부러 '자동 정렬' 같은 키워드를 그대로 놔 뒀다.
위 내용은 힙을 알아야 이해가 될 부분인 것 같다.
그럼 바로 위 설명을 약간 정리한 다음에 힙을 좀 보고가자.
안 그러면 계속 헷갈릴 거 같아서.
=> 다시 정리한, 프라이어리티큐 작동 방식
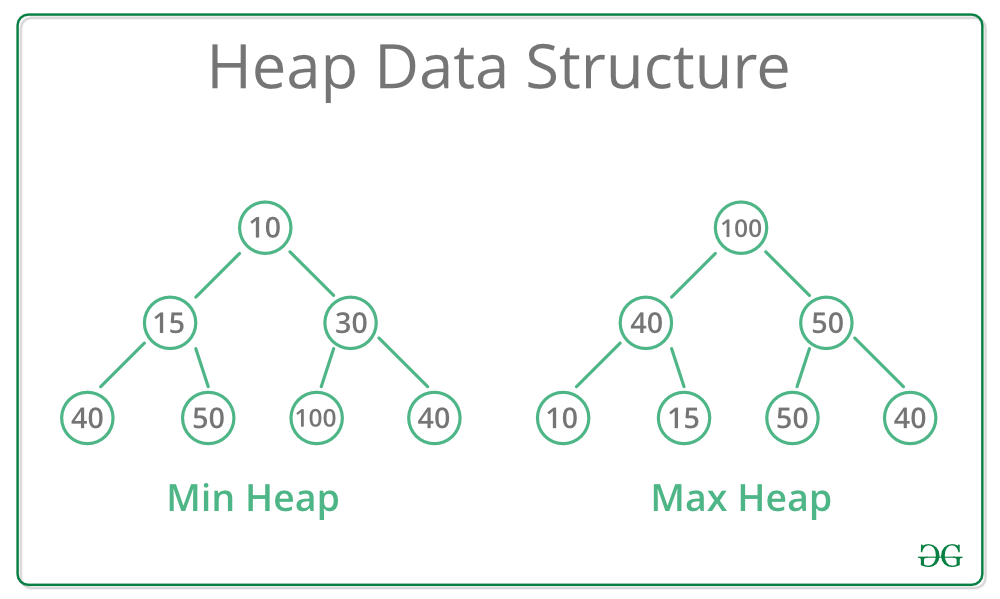
프라이어리티큐는 내부적으로 힙 자료구조를 사용한다.
힙은 Min Heap과 Max Heap이 있다.
요소가 삽입되면 정렬은 '자동'으로 된다. 그런데 이미지 보면 알겠지만 '온전한 정렬 상태'가 아니다.
Min Heap을 보면 맨 아래 노드(leaf node라고 한다.)가 40, 50, 100, 40으로 '엉망'이다.
이 힙이 진짜 완벽히 정렬됐다면
10-15-30-40-40-50-100 이렇게 되어야 한다.
리프 노드가 40-40-50-100이렇게 되어야 한다는 말이다.
그런데 그렇지가 않다.
그래서 반 정렬 상태라고 표현한 것이다.
'바로 정렬이 안 된다', <- 정렬됨. 'full' 정렬이 안 된다 그 소리임.
'전체 정렬 상태 유지 안 함', <- 모든 노드가 완벽히 정렬된 상태가 아니고 '상대적으로' 정렬된 상태라는 소리임.
라는 말의 뜻은 이러하다.
내가 위에서 힙 좀 보고 가자고 했는데 다시 보니까 지금 상태에서는 굳이 안 봐도 될 것 같다.
굳이 완벽히 알고 가고 싶은 분은
https://www.geeksforgeeks.org/heap-data-structure/
Heap Data Structure - GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
여기서 보시면 되겠다.
자, 그럼 다시 프라이어리티큐로 돌아와서, 메서드를 보자.
주요 메서드
- offer(E e): 요소를 큐에 추가합니다. add(E e)와 같지만, 용량 제한에 도달했을 때 다른 동작을 합니다.
- poll(): 큐에서 가장 우선 순위가 높은 요소를 제거하고 반환합니다. 큐가 비어있을 경우 null을 반환합니다.
- peek(): 큐에서 가장 우선 순위가 높은 요소를 반환하지만 제거하지는 않습니다. 큐가 비어있을 경우 null을 반환합니다.
- remove()와 element(): poll()과 peek()과 유사하지만, 큐가 비어 있을 경우 예외를 던집니다.
import java.util.PriorityQueue;
public class Example {
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
priorityQueue.offer(10);
priorityQueue.offer(20);
priorityQueue.offer(15);
System.out.println("Priority queue top: " + priorityQueue.peek()); // 출력: 10
while (!priorityQueue.isEmpty()) {
System.out.println(priorityQueue.poll()); // 출력: 10, 15, 20
}
}
}
데이터가 10-20-15로 들어갔다가 제일 작은 것부터 poll되는데 10이 뽑히면 15-20 이렇게 자동 정렬이 된다.
그래서 15, 20순으로 나오는 것.
활용 예
- 데이터 스트림의 최소/최대 요소 관리: 실시간 데이터 피드에서 항상 최소 또는 최대 값을 유지해야 할 때 사용할 수 있습니다.
- 다익스트라 알고리즘(Dijkstra's algorithm): 최단 경로를 찾을 때 우선 순위 큐를 사용하여 다음에 탐색할 가장 가까운 노드를 결정합니다.
- 허프만 코딩(Huffman Coding): 데이터 압축에서 가장 적은 빈도의 노드부터 처리하여 트리를 구성할 때 사용합니다.
프라이어리티큐는 이 정도 보면 될 거 같고, 이제 문제 풀러 가자~!
'자바 > 자바 자료구조' 카테고리의 다른 글
| 자바 - Deque 이야기 (0) | 2024.04.27 |
|---|---|
| 자바 - PriorityQueue로 코테 푸는 법 (0) | 2024.04.27 |
| 자바 - Queue의 LinkedList 이야기와 이걸로 코테 푸는 법 (0) | 2024.04.27 |
| [묘공단] 자바 - Queue 이야기 (0) | 2024.04.27 |
| 자바 - Stack 및 Vector로 코테 푸는 법 (0) | 2024.04.27 |



